

作为一个多端开发框架,Taro 从项目发起时就已经支持编译到 H5 端。随着 Taro 多端能力的不断成熟,我们对 Taro H5 端应用的要求也不断提升。我们已经不再满足于“能跑”,更希望 Taro 能跑得快。
我们经常收到用户反馈:为什么使用 Taro 脚手架创建的空项目,打包后代码体积却有 400KB+;也有用户在 Issue 中提到,Taro 的部分 Api 占用空间巨大,事实上功能却并不完美,等等。作为一个开源项目,我们非常重视社区开发者们的意见。所以在最新版本中,我们对 Taro H5 端的性能表现进行了优化。
作为运行时的基础,每一个 Taro 的 H5 端应用都需要引入 @tarojs/components 和 @tarojs/taro-h5 等基础依赖包。在编译、打包之后,这些依赖包大约会在首屏占用 400KB 以上的空间。如果开发者还使用了 UI 库,例如 Taro-UI,基础体积还会更大,这严重限制了 Taro H5 端应用的性能优化空间。
事实上,我们在 H5 端应用中并不会使用到全部的 Taro 组件和 Api。将这些依赖包全部打包进应用是没有必要,也是不合理的。进行死码删除(Dead code elimination),进一步缩减代码体积,就是我们的优化方向之一。
效果
在介绍具体细节之前,我们先看一看优化的效果,因为这可能会让你更有兴趣了解后面的内容。用一句话来说,效果非常显著。
我们建立了一个空项目,在项目配置中加入了webpack-bundle-analyzer插件以查看编译分析。下图是优化前的打包文件分析结果:

而在优化后,对比非常明显:

优化前生成的代码总大小为 455KB,而在优化后仅剩约 96KB,仅是原来的 1/5 左右。
你需要做什么
很简单,作为使用者,你不需要做任何代码上的改动,只需要将 Taro 更新到最新版本即可。但在看不见的地方,Taro 却默默地做了许多工作。下面会从原理出发,详细介绍 Taro 的工作。
原理
死码删除(Dead code elimination)是一种代码优化技术,可以删除对应用程序执行结果没有影响的代码。Web Fundamentals 的一篇文章有提到,treeshaking 是由 Rollup 提出的一种死码删除的形式。
Tree shaking is a form of dead code elimination. The term was popularized by Rollup, but the concept of dead code elimination has existed for some time.
-- Reduce JavaScript Payloads with Tree Shaking, Jeremy Wagner
通过在构建时进行静态分析,编译工具可以分析出我们代码中真正的依赖关系。treeshaking 把我们的代码想象成一棵树,代码的每个依赖项看作树上的节点。将未使用过的依赖项从构建结果中移除,这就是 treeshaking 的基本思想。
那么,假设我们手头有一段代码,我们要怎样辨别其中可以删除的部分呢?答案是,通过分析副作用:
// add.js
export default function add(a, b){ return a + b; }
// add2.js
console.log('这是一个log')
export default function add2(a, b){ return a + b; }
// index.js
import add from './add.js' // 没有副作用,可以删除
import add2 from './add2.js' // 有副作用,不能直接删除
// EOF
副作用这个名词对于了解函数式编程的同学肯定不陌生。修改外部状态,或者是产生输出等等,都是副作用;而存在副作用的代码,是不能被直接移除的。类似上面这个代码示意,add2 模块就是存在副作用的。
站在巨人的肩膀上
除了 Rollup 之外,支持 treeshaking 的工具/插件还有很多,比如 babel-plugin-transform-dead-code-elimination、uglify、terser等。 webpack 在 v2 之后就内置了对 treeshaking 的支持,并在 webpack@4 中对 treeshaking 功能进行了扩展。
Taro H5 端在构建过程中,使用 webpack 作为构建的核心。在 webpack 中使用 treeshaking 功能有几个需要注意的地方:
- 如果是 npm 模块,需要
package.json中存在sideEffects字段,并且准确配置了存在副作用的源代码。 - 必须使用 ES6 模块语法。由于诸如
babel-preset-env之类的 babel 预配置包默认会对代码的模块机制进行改写,还需要将modules设置为false,将模块解析的工作直接交给 webpack。 - 需要工作在 webpack 的
production模式下。
webpack 的 treeshaking 工作主要分为两步。第一步是在模块级别移除未使用且无副作用的模块,这一步由 webpack 的内置插件完成;第二步是在文件级别移除未使用的代码,这一步由代码压缩工具 Terser 完成的。
移除未使用的模块
前面我们提到,需要在package.json中配置sideEffects字段。
在 webpack 文档 中有提到,这一举动正是为了让 webpack 正确地识别到没有副作用的代码模块。
在 webpack 中,模块依赖分析是由内置插件 SideEffectsFlagPlugin 进行的。
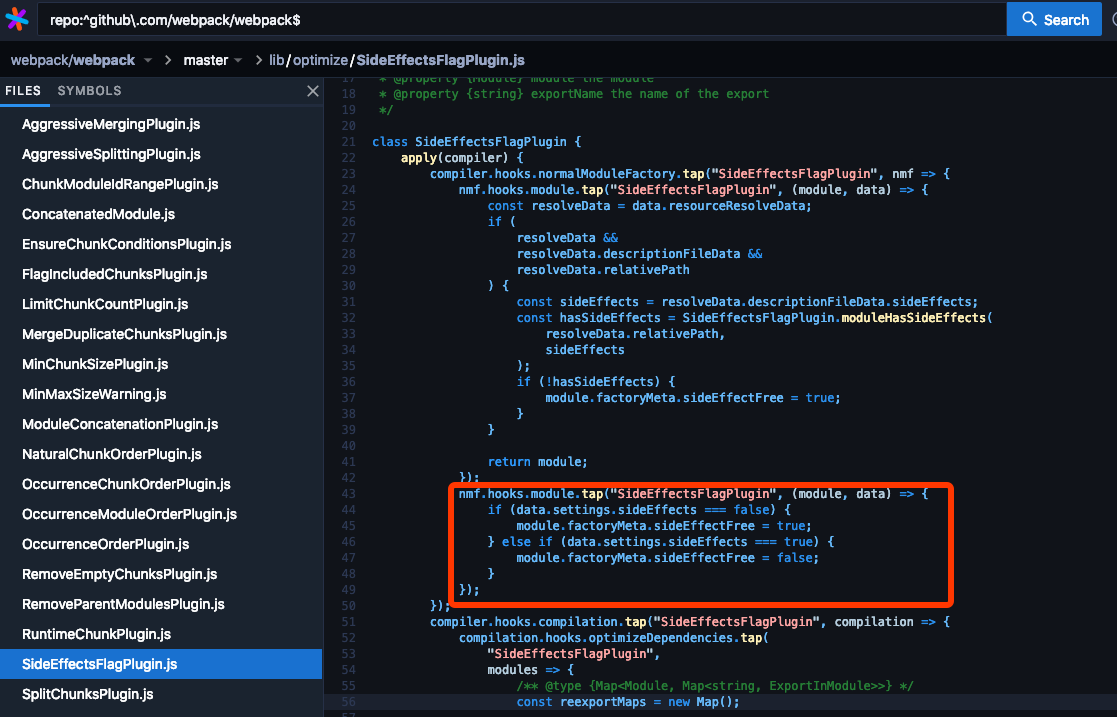
经过 SideEffectsFlagPlugin处理后,没有使用过并且没有副作用的模块都会被打上sideEffectFree标记。
在 ModuleConcatenationPlugin 中,带着sideEffectFree标记的模块将不会被打包:
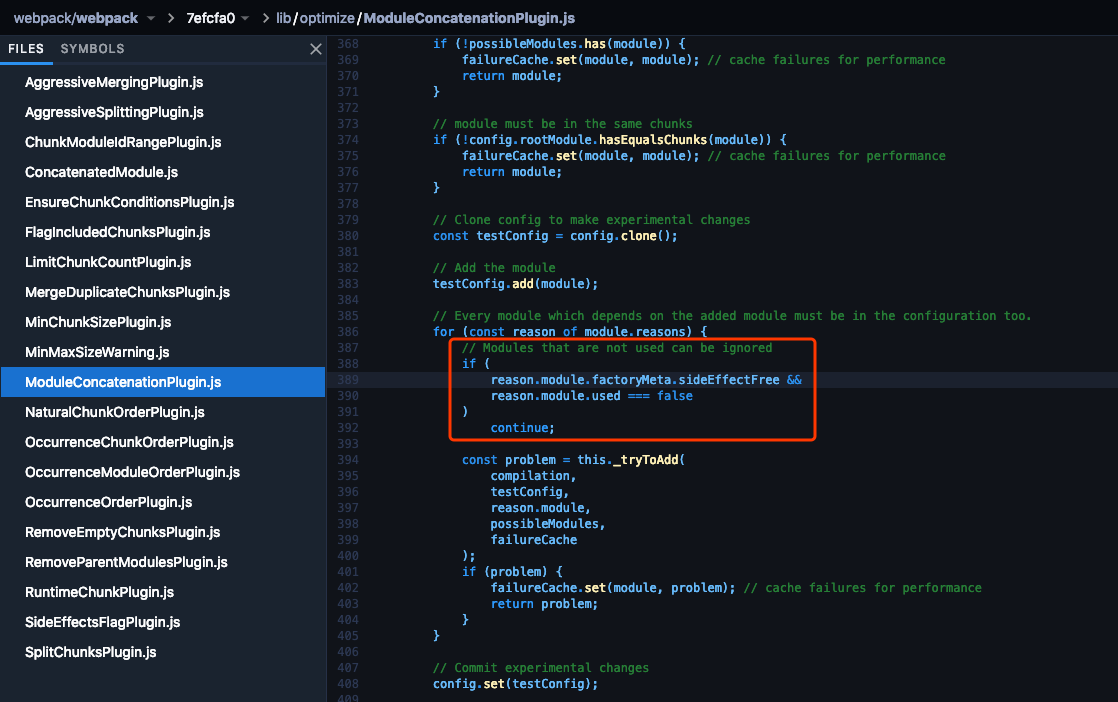
来到这里,webpack 完成了在模块级别对未使用模块的排除。接下来,依靠 Terser,webpack 可以在文件级别,对未使用、无副作用的代码进行移除。
移除未使用的代码
在 CommonJS 规范中,我们通过require函数来引入模块,通过module.exports进行导出。这意味着我们可以在代码中的任何地方用任何方式引入和导出模块:可以是在某个需要等待用户输入的回调函数中,或者是在符合某个条件才进行引入等等。所以在使用 ES6 的模块系统之前,对 Javascript 做编译时的依赖关系分析是近乎不可能的(并不是完全不可能。prepack 通过实现一个 JS 解释器,甚至可以在编译时提前进行静态计算)。
// utils.js
module.exports.add = function (a, b) { return a + b };
module.exports.minus = function (a, b) { return a - b };
// index.js;
var utils = require('./utils.js');
utils.add(1, 2);
像上面这段代码,虽然我们最终只使用了add函数,但minus函数也会在最终的打包代码中出现,因为在编译时无法快速得知是否使用了minus函数。
在 ES6 的模块系统中,我们使用import/export语法来进行模块的引入和导出。与 CommonJS 规范不同的是,这套新的模块系统存在一些限制:import/export行为只能在代码的顶层、默认使用严格模式等等。这些限制使代码模块的导入与导出变得静态化,模块间的依赖关系在开发时已经确定,编译器也更容易解析我们的代码。
// utils.js
export function add (a, b) { return a + b };
export function minus (a, b) { return a - b };
// index.js;
import { add } from './utils.js';
add(1, 2);
在使用 ES6 模块系统改造后,我们可以清楚地看到,minus函数确实没有被使用过,所以可以安全地将其从最终打包代码中移除。
当然,具体的分析过程非常复杂。变量提升、object 取值操作、for(var i in list) 语句、自执行函数、函数传参(onClick(function a () {…}))等等,都有可能导致意料之外的情况,从而导致 treeshaking 失效。如果想了解 Terser 的具体处理过程,百度/Google 会是最好的老师。
Taro 做了什么
Taro 需要对依赖包做一些修改。
组件的 ES 模块化
在进行组件库的 ES 模块化改造之前,如果要发布 @tarojs/components 包,Taro 会执行命令 yarn build,使用 webpack 对源代码进行打包,输出为dist/index.js文件。由于 webpack 并不支持输出为 ES 模块,所以这是个 UMD 模块。
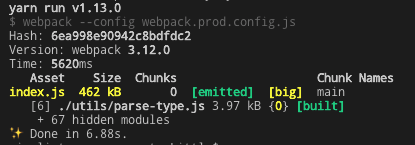
这个文件占据了 462KB 的空间,并且由于模块规范等问题,无法进行 treeshaking。所以就算开发者在 Taro 的项目中只引入了两个组件,最终的打包结果也会包含所有的内置组件。
事实上,@tarojs/components 的源码本身是使用 ESM 规范的:
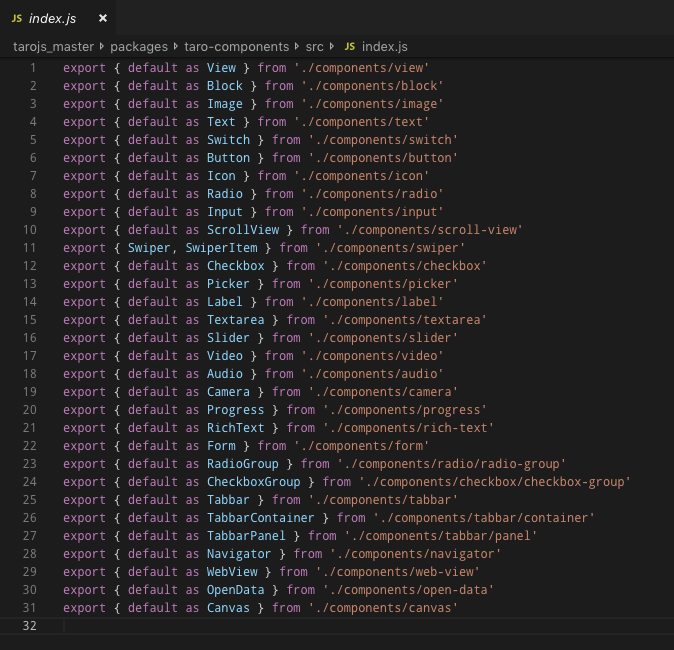
所以只要让 webpack 直接解析组件库的源码,我们立即就可以享受到 webpack 自带 treeshaking 带来的好处了。
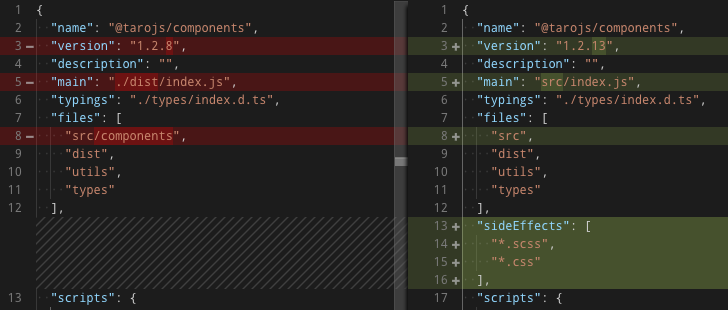
同时,我们也在sideEffects属性中对样式文件做了标记,帮助 webpack 对样式代码的副作用进行识别,在项目编译的代码中保留样式代码。
Api 的 ES 模块化
同样,以前在发布 @tarojs/taro-h5 之前,Taro 也需要执行命令 yarn build,使用 Rollup 对源代码进行打包,输出为dist/index.js文件:
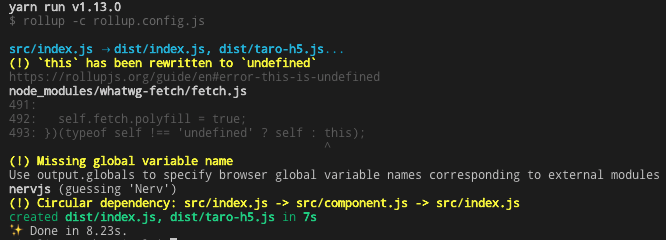
这个文件占据了 262KB 的空间。同样,只要是个 Taro 的 H5 端应用,生成的代码都会全量引入这个文件。
我们对 @tarojs/taro-h5 进行模块化改造的思路与 @tarojs/components 相同。我们希望 @tarojs/taro-h5 模块本身遵守 ESM 模块规范,那就只需要标记一下sideEffects,再修改一下模块入口就好。
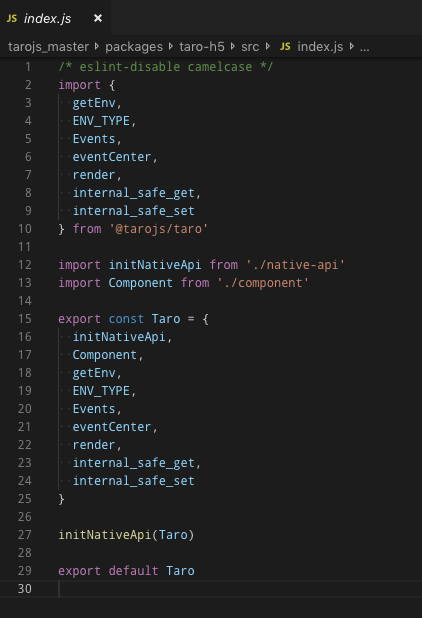
粗略一看,@tarojs/taro-h5 还挺 “ESM” 的,但这还不够。我们还需要将这些 Api 以 namedExports 的形式导出,开发者使用import { XXX } from '@tarojs/taro-h5'导入 Api 即可。
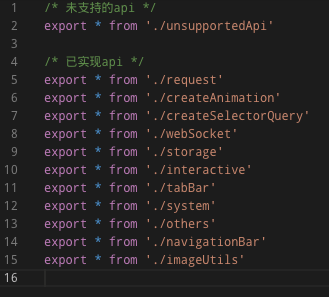
那么问题来了。在 Taro 项目中,我们一直使用的是 defaultImport,并不会使用 Api 的 namedExports 形式:
import Taro from '@tarojs/taro-h5'
Taro.navigateTo()
Taro.getSystemInfo()
// Taro.xxx ...
只要 Api 是通过对Taro变量取属性获取,Taro变量就需要具备所有的 Api,treeshaking 也就无从谈起。
有没有办法把 defaultImport 修改为 namedImports 呢?答案是肯定的。我们写了一个 babel 插件 babel-plugin-transform-taroapi,将指定的 Api 调用替换为 namedImports,未指定的变量则保留属性取值的形式。具体源码可以在这里查看。
// const apis = new Set(['navigateTo', 'navigateBack', ...])
{
babel: {
preset: ['babel-preset-env'],
plugins: [
// ...,
['babel-plugin-transform-taroapi', {
packageName: '@tarojs/taro-h5',
apis
}]
]
}
}
这个插件接受一个对象作为配置参数:packageName属性指定需要进行替换的模块名,apis接受一个 Set 对象,也就是所有 Api 的列表。
为了避免后期手动维护 Api 列表的情况,我们给 @tarojs/taro-h5 模块加了一个编译任务,通过一个简单的Rollup 插件,在执行yarn build命令时生成一份 Api 列表:
下面是编译前后的代码对比。可以看到,在编译后setStorage、getStorage的调用都被替换为 namedImports。
// 编译前
import Taro from '@tarojs/taro-h5';
Taro.initPxTransform({});
Taro.setStorage()
Taro['getStorage']()
// 编译后
import Taro, { setStorage as _setStorage, getStorage as _getStorage } from '@tarojs/taro-h5';
Taro.initPxTransform({});
_setStorage();
_getStorage();
到这里,虽然过程比较艰辛,但我们对 @tarojs/taro-h5 的模块化改造终于完成了。
最后
截至目前,Taro 在 H5 端的完成度已经很高,但是并不完美。未来,在对已有问题进行修复的同时,我们还将继续为 Taro H5 端带来更多新的特性,比如对社区中呼声相当高的switchTab、页面滚动监听onPageScroll、下拉刷新onPullDownRefresh等 Api 的支持,更加统一的页面切换动画,以及更加稳定的多页面模式等等。
Taro 发展到现在,离不开社区的支持。非常感谢在 github、微信群中踊跃反馈的开发者们。如果你对Taro有什么想法或建议,Taro 非常欢迎你来吐槽或观光: